基于MinIO的分离式HDP Spark和Hive
1. 云原生架构
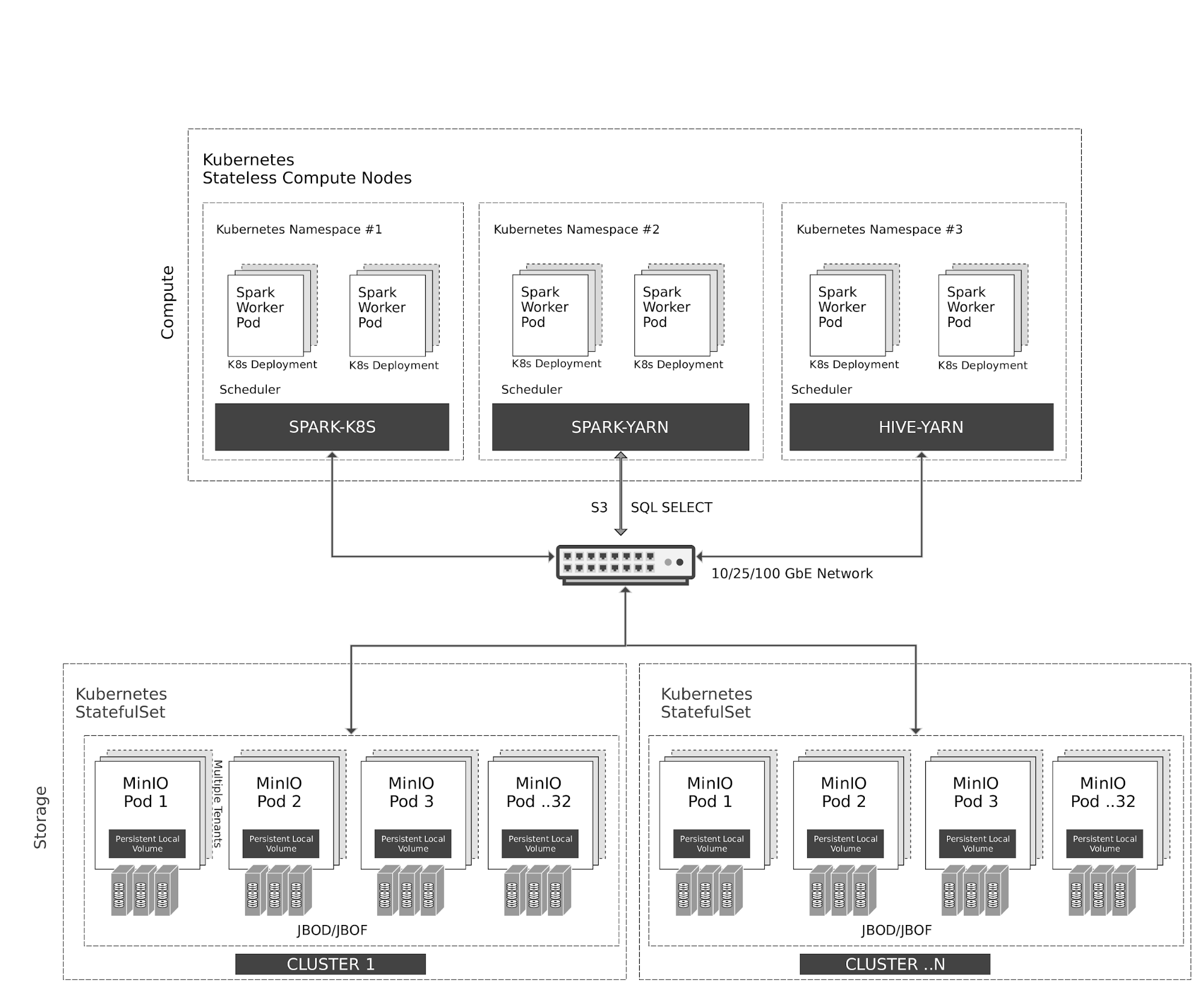
Kubernetes在计算节点上弹性管理无状态的Spark和Hive容器。Spark与Kubernetes具有原生调度器集成。由于历史原因,Hive在Kubernetes之上使用YARN调度器。
所有对MinIO对象存储的访问都通过S3/SQL SELECT API进行。除了计算节点外,MinIO容器也由Kubernetes作为有状态容器进行管理,并将本地存储(JBOD/JBOF)映射为持久化本地卷。这种架构支持多租户MinIO,实现了客户间的数据隔离。
MinIO 还支持多集群、多站点联邦,类似于 AWS 的区域和层级。通过 MinIO 信息生命周期管理(ILM),您可以配置数据在基于 NVMe 的热存储和基于 HDD 的温存储之间进行分层。所有数据都使用每个对象的密钥进行加密。租户之间的访问控制和身份管理由 MinIO 使用 OpenID Connect 或 Kerberos/LDAP/AD 进行管理。
2. 先决条件
使用此方法安装 Hortonworks Distribution指南。
使用以下任一指南安装 MinIO 分布式服务器。
3. 配置 Hadoop、Spark、Hive 使用 MinIO
成功安装后,请导航至 Ambari UIhttp://<ambari-server>:8080/并使用默认凭据登录:[username: admin, password: admin]
3.1 配置 Hadoop
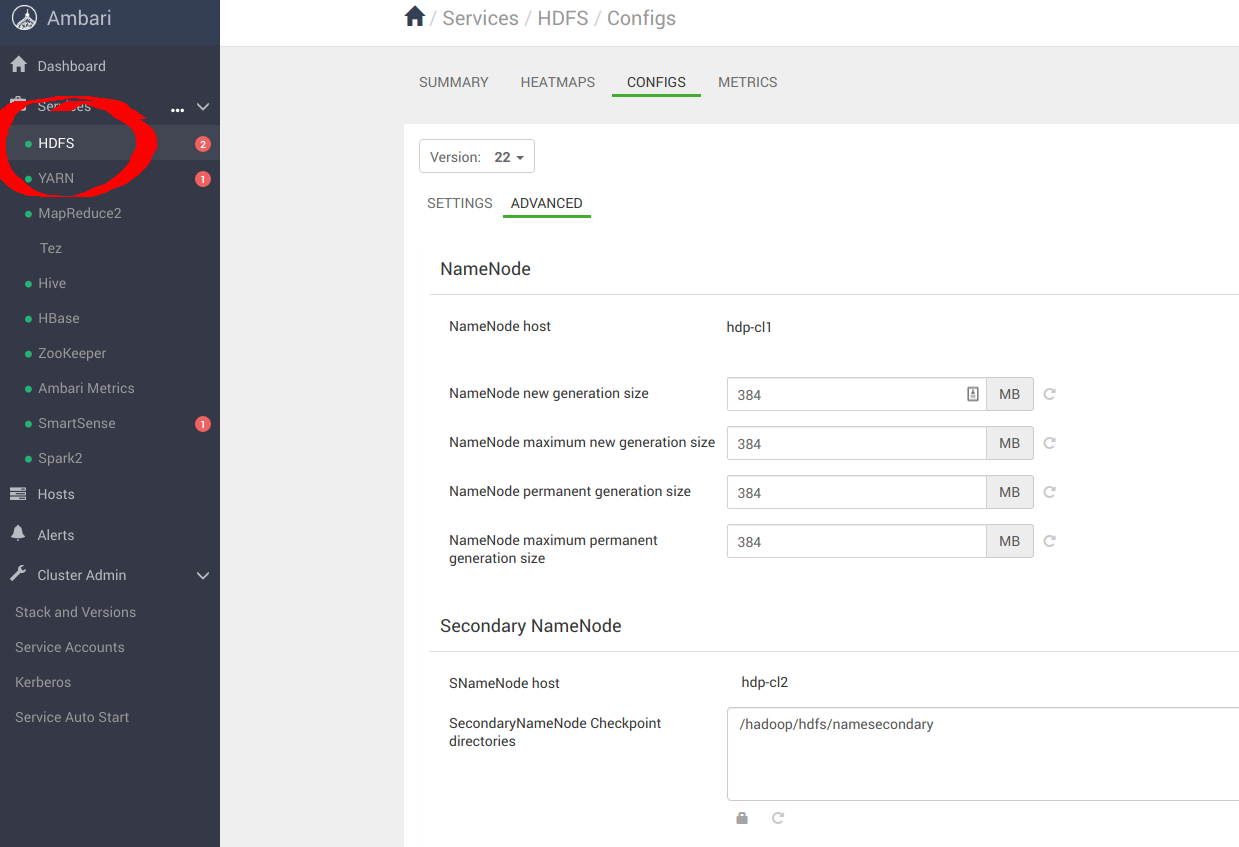
Navigate to服务->HDFS->CONFIGS->高级如下所示
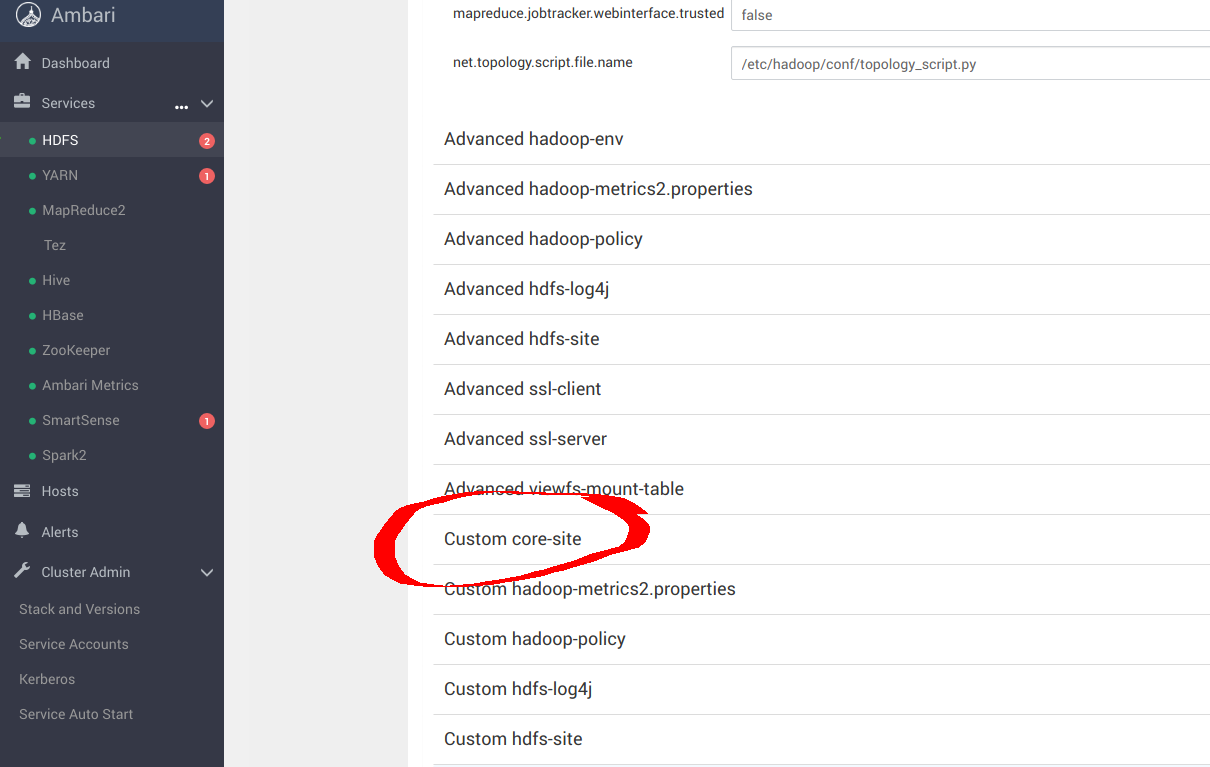
Navigate to自定义核心站点配置 MinIO 参数_s3a_连接器
sudo pip install yq
alias kv-pairify='yq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'
让我们以一组12个计算节点为例,其总内存容量为1.2TiB,我们需要进行以下设置以获得最佳结果。添加以下最佳条目:core-site.xml配置s3awithMinIO这里最重要的选项是
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
mapreduce.reduce.speculative=false # Disable speculation for reducing
mapreduce.task.io.sort.factor=999 # Threshold before writing to drive
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive
S3A是用于连接S3及其他S3兼容对象存储(如MinIO)的接口。MapReduce工作负载与对象存储的交互方式通常与其与HDFS的交互方式相同。这些工作负载依赖HDFS原子重命名功能来完成数据写入存储库的操作。对象存储操作本质上是原子性的,因此不需要/未实现重命名API。默认的S3A提交器通过复制和删除API来模拟重命名操作。由于写入放大效应,这种交互模式会导致显著的性能损失。Netflix例如,开发了两种新的暂存提交器——目录暂存提交器和分区暂存提交器——以充分利用原生对象存储操作。这些提交器不需要重命名操作。我们对这两种暂存提交器以及另一个名为Magic提交器的新增功能进行了基准测试评估。
经测试发现,目录暂存提交器是三者中速度最快的,为获得最佳性能,S3A连接器应配置以下参数:
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "s3a"
fs.s3a.access.key=minio
fs.s3a.secret.key=minio123
fs.s3a.path.style.access=true
fs.s3a.block.size=512M
fs.s3a.buffer.dir=${hadoop.tmp.dir}/s3a
fs.s3a.committer.magic.enabled=false
fs.s3a.committer.name=directory
fs.s3a.committer.staging.abort.pending.uploads=true
fs.s3a.committer.staging.conflict-mode=append
fs.s3a.committer.staging.tmp.path=/tmp/staging
fs.s3a.committer.staging.unique-filenames=true
fs.s3a.connection.establish.timeout=5000
fs.s3a.connection.ssl.enabled=false
fs.s3a.connection.timeout=200000
fs.s3a.endpoint=http://minio:9000
fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.committer.threads=2048 # Number of threads writing to MinIO
fs.s3a.connection.maximum=8192 # Maximum number of concurrent conns
fs.s3a.fast.upload.active.blocks=2048 # Number of parallel uploads
fs.s3a.fast.upload.buffer=disk # Use drive as the buffer for uploads
fs.s3a.fast.upload=true # Turn on fast upload mode
fs.s3a.max.total.tasks=2048 # Maximum number of parallel tasks
fs.s3a.multipart.size=512M # Size of each multipart chunk
fs.s3a.multipart.threshold=512M # Size before using multipart uploads
fs.s3a.socket.recv.buffer=65536 # Read socket buffer hint
fs.s3a.socket.send.buffer=65536 # Write socket buffer hint
fs.s3a.threads.max=2048 # Maximum number of threads for S3A
其余优化选项的讨论请参见以下链接
https://hadoop.apache.org/docs/current/hadoop-aws/tools/hadoop-aws/index.html
https://hadoop.apache.org/docs/r3.1.1/hadoop-aws/tools/hadoop-aws/committers.html
配置更改应用后,请继续执行重启操作Hadoop服务。
3.2 配置 Spark2
Navigate to服务->Spark2->CONFIGS如下所示
Navigate to “Custom spark-defaults”以配置 MinIO 参数_s3a_连接器
添加以下最佳条目:spark-defaults.conf配置 SparkMinIO.
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.block.size 512M
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
spark.hadoop.fs.s3a.committer.magic.enabled false
spark.hadoop.fs.s3a.committer.name directory
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
spark.hadoop.fs.s3a.connection.establish.timeout 5000
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.connection.timeout 200000
spark.hadoop.fs.s3a.endpoint http://minio:9000
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A
配置更改应用后,请继续执行重启操作Spark服务。
3.3 配置 Hive
Navigate to服务->Hive->CONFIGS->高级如下所示
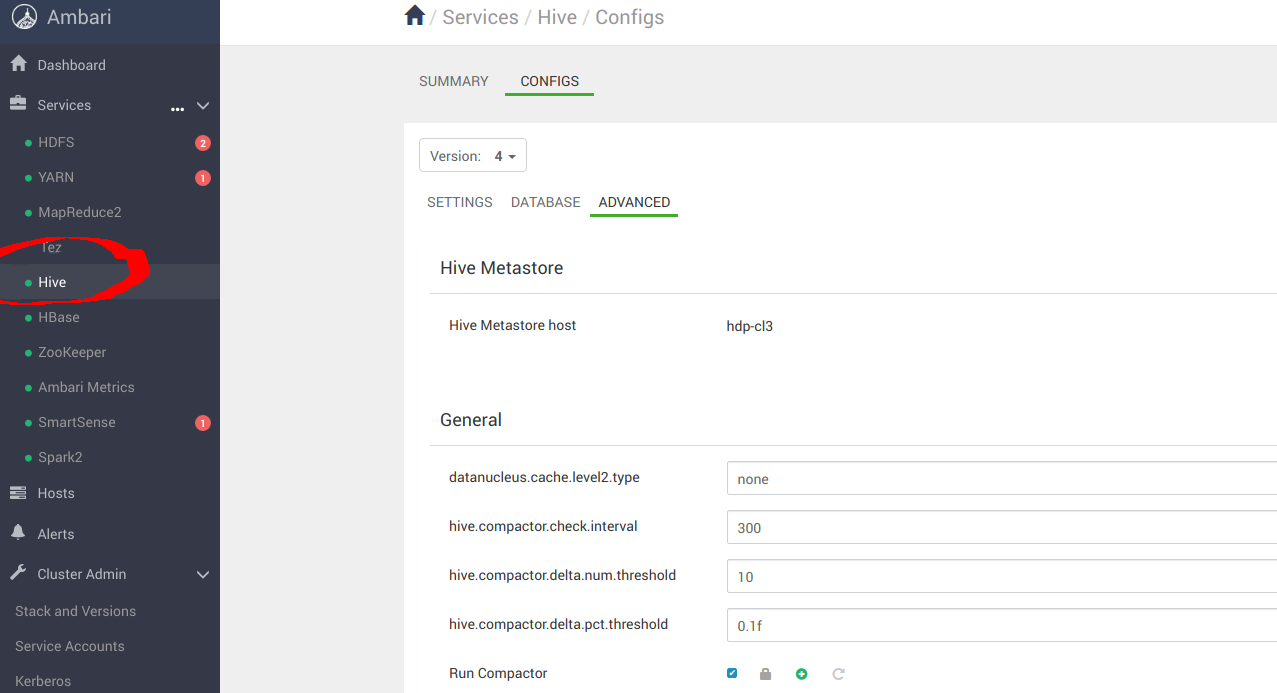
Navigate to “Custom hive-site”以配置 MinIO 参数_s3a_连接器
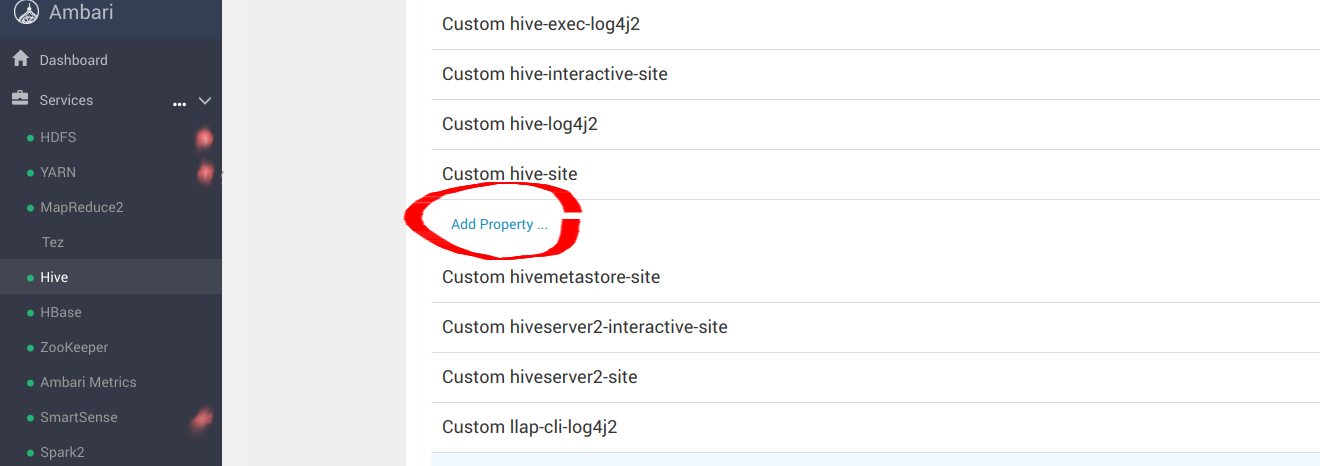
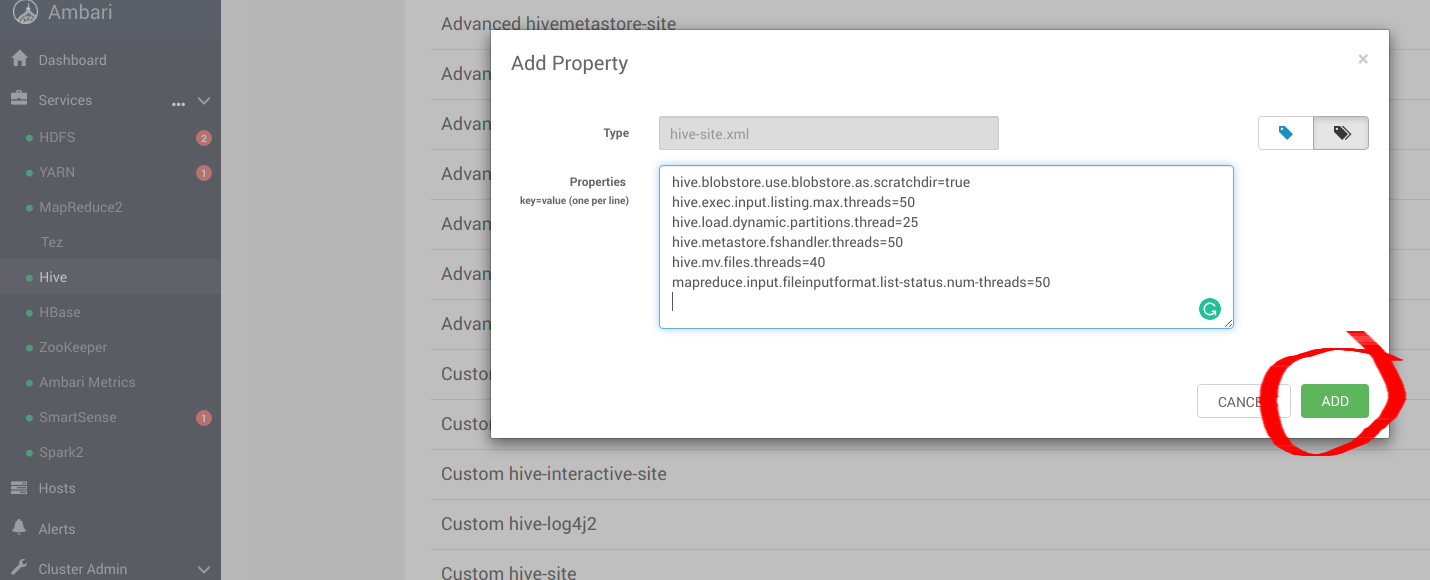
添加以下最佳条目:hive-site.xml配置 HiveMinIO.
hive.blobstore.use.blobstore.as.scratchdir=true
hive.exec.input.listing.max.threads=50
hive.load.dynamic.partitions.thread=25
hive.metastore.fshandler.threads=50
hive.mv.files.threads=40
mapreduce.input.fileinputformat.list-status.num-threads=50
如需了解这些选项的更多信息,请访问https://www.cloudera.com/documentation/enterprise/5-11-x/topics/admin_hive_on_s3_tuning.html
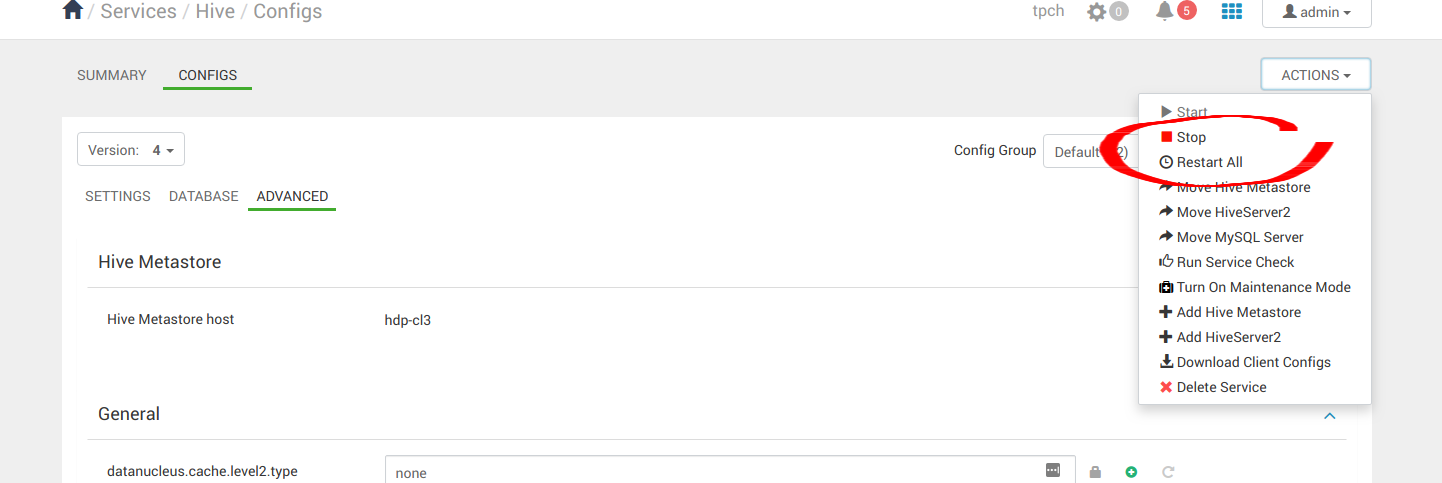
配置更改应用后,请继续重启所有 Hive 服务。
4. 运行示例应用程序
在成功安装Hive、Hadoop和Spark之后,我们现在可以继续运行一些示例应用程序来验证它们是否配置正确。我们可以使用Spark Pi和Spark WordCount程序来验证Spark安装。我们还可以探索如何从命令行和Spark shell运行Spark作业。
4.1 Spark Pi
通过运行以下计算密集型示例来测试 Spark 安装,该示例通过向圆形"投掷飞镖"的方式计算圆周率。程序会在单位正方形(从 (0,0) 到 (1,1))内生成随机点,并统计落在正方形内单位圆中的点数。最终结果将近似圆周率值。
按照以下步骤运行 Spark Pi 示例:
以用户身份登录'spark'.
当作业运行时,该库现在可以使用MinIO在中间处理过程中。
导航到具有 Spark 客户端的节点并访问 spark2-client 目录:
cd /usr/hdp/current/spark2-client
su spark
在 yarn-client 模式下运行 Apache Spark Pi 作业,使用来自org.apache.spark:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-client \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
examples/jars/spark-examples*.jar 10
该作业应产生如下所示的输出。请注意输出中π的值。
17/03/22 23:21:10 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.302805 s
Pi is roughly 3.1445191445191445
作业状态也可以在浏览器中查看,方法是导航到 YARN ResourceManager Web UI 并点击作业历史服务器信息。
4.2 WordCount
WordCount 是一个简单的程序,用于统计单词在文本文件中出现的频率。该代码构建了一个名为 counts 的 (String, Int) 键值对数据集,并将数据集保存到文件中。
以下示例将WordCount代码提交到Scala shell。为Spark WordCount示例选择一个输入文件。我们可以使用任何文本文件作为输入。
以用户身份登录'spark'.
当作业运行时,该库现在可以使用MinIO在中间处理过程中。
导航到具有 Spark 客户端的节点并访问 spark2-client 目录:
cd /usr/hdp/current/spark2-client
su spark
以下示例使用log4j.properties作为输入文件:
4.2.1 将输入文件上传到HDFS:
hadoop fs -copyFromLocal /etc/hadoop/conf/log4j.properties
s3a://testbucket/testdata
4.2.2 运行 Spark shell:
./bin/spark-shell --master yarn-client --driver-memory 512m --executor-memory 512m
该命令应产生如下所示的输出(包含额外的状态消息):
Spark context Web UI available at http://172.26.236.247:4041
Spark context available as 'sc' (master = yarn, app id = application_1490217230866_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0.2.6.0.0-598
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
在scala>提示,通过输入以下命令提交作业,将节点名称、文件名和文件位置替换为您的值:
scala> val file = sc.textFile("s3a://testbucket/testdata")
file: org.apache.spark.rdd.RDD[String] = s3a://testbucket/testdata MapPartitionsRDD[1] at textFile at <console>:24
scala> val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> counts.saveAsTextFile("s3a://testbucket/wordcount")
使用以下方法之一查看作业输出:
在 Scala shell 中查看输出:
scala> counts.count()
364
要查看 MinIO 的输出,请退出 Scala shell。查看 WordCount 作业状态:
hadoop fs -ls s3a://testbucket/wordcount
输出应该类似于以下内容:
Found 3 items
-rw-rw-rw- 1 spark spark 0 2019-05-04 01:36 s3a://testbucket/wordcount/_SUCCESS
-rw-rw-rw- 1 spark spark 4956 2019-05-04 01:36 s3a://testbucket/wordcount/part-00000
-rw-rw-rw- 1 spark spark 5616 2019-05-04 01:36 s3a://testbucket/wordcount/part-00001